A few months ago I wanted to test the Orange3 platform to analyze how a no-code tool works and explore data using Natural Language Processing (NLP). Something quick. I didn’t want to “waste” too much time experimenting. The questions were very basic: how do I ingest the data, how do I process it, what kind of tasks do I need, do I apply traditional techniques or language models, … Let’s take it one step at a time.
What do I mean by no-code NLP?
In short: extract knowledge from a corpus of documents without the need to generate code. As simple as that. With all that it implies:
- You do not have to install Python or R or any other programming language (although it is very useful to know them).
- No development environments (IDE)
- No need to struggle with dependency, syntax or library update errors.
- We will focus on the logic of the problem: NLP is a tool for doing something. Let’s analyze what I want to know about this “something”.
- Are you more comfortable with workflows? With visual programming? That is, no-code NLP. That’s the key.
Let’s start with the tools. Nothing complicated. Just a first glance to take away the fear.
Tools I use for no-code NLP
In this field, I have two main tools: KNIME Analytics Platform and Orange Data Mining. Both are Open Source. This time, the example will be with Orange, but to be honest, right now I only use KNIME. I even wrote an article for their magazine on Medium. Here are the main ones I have on my radar for these issues.
| Tool | Website | Download | Resources | YouTube | |
|---|---|---|---|---|---|
| KNIME Analytics Platform | knime | Mac / PC / Linux | Academia / Blog | @knime | KNIMETV |
| Orange Data Mining | orangedatamining | Mac / PC / Linux | Doc / Blog | @orangedataminer | Orange |
| Dataiku DSS | dataiku | All platforms and Cloud | Learn | @dataiku | Dataiku |
Why do I like these tools?
In particular, the KNIME Analysis Platform.
- Open Source version available. If you want to use it in a professional environment, KNIME and Dataiku have enterprise products in their Server versions.
- As it is a visual programming, the learning curve for a programming beginner is lower. This does not mean that it is not interesting to know how to program. In fact, if you are proficient in Python or R, its integrations will allow you to exploit its capabilities much more.
- All of them have training channels with very simple tutorials that allow you to start testing in a very easy way. And the results are not a “hello world”. They are, or can be, real. It just depends on the data you get.
- They have very active development communities: new nodes, blogs, books, … if you ever get stuck somewhere, take a look at the forums. It is likely to be solved or at least, you will be given clues to move forward.
- Availability of libraries, add-ons, extras focused on specific topics, e.g. no-code NLP.
- You get results in a very fast way that prevents you from abandoning your study.
No-code NLP examples with real data
Let’s start with an example. In this case, we will use Orange:
- Objective: in the context of the European Commission’s Horizon2020 research program, to identify the topics that are related to each other within the “Connected Car” areas.
- Data: List of H2020 call topics with codeID, title and objectives.
- I have filtered the topics related to “connected car”, “autonomous vehicle”, “transportation”, … to see how they relate to each other.
- Here is the link to the CSV file with the data on the EU Open Data Portal website.
- Tools: Orange3 with the Text Mining add-on. Here is a list of the different widgets available.
- It was my first test with Orange3 so comments are welcome. I leave you a link with the workflow so you don’t have to generate it from scratch.
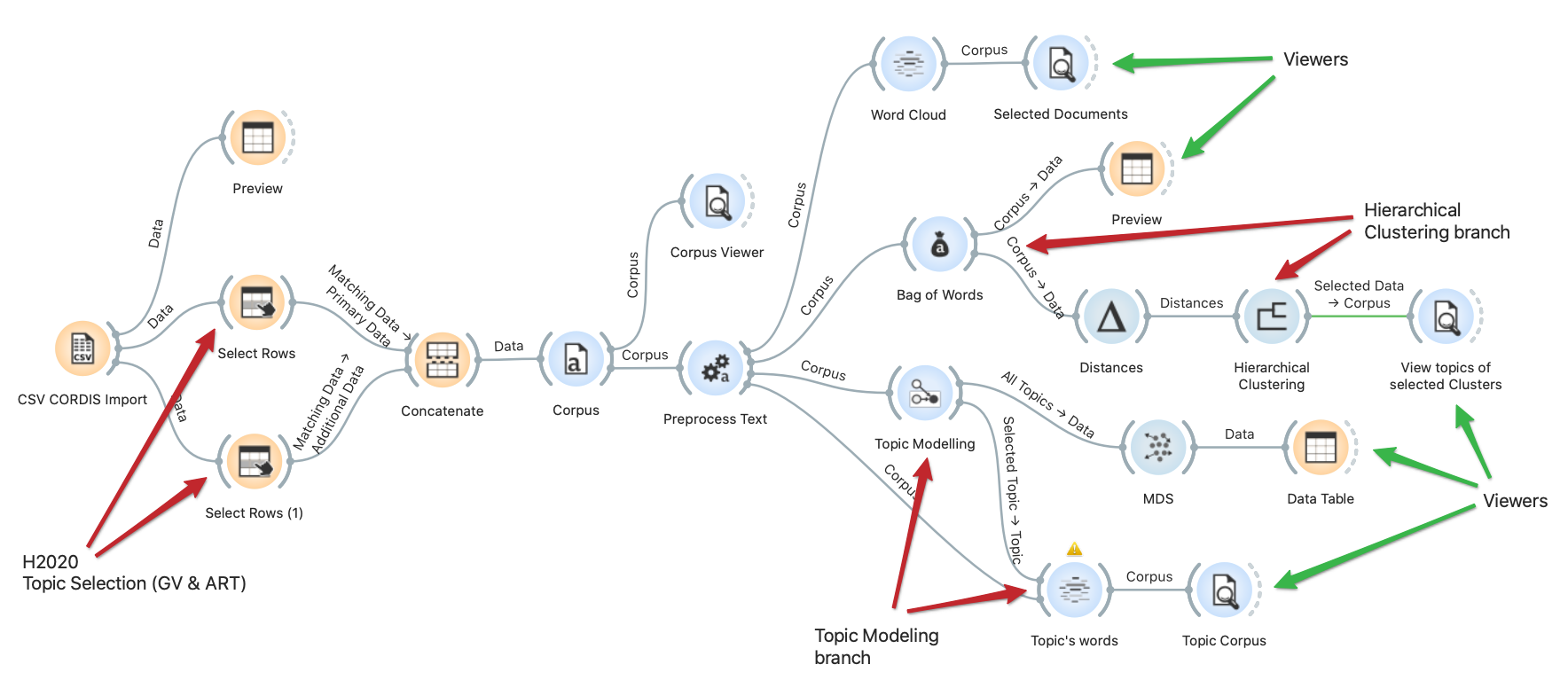
Example
As I said, I have used the English topics related to transportation *ART* and *GV*. In total there are 43 topics that include the codeID, the title and the objectives of the topic. For example:
| codeID | Title | Target |
|---|---|---|
| GV-2-2014 | Optimised and systematic energy management in electric vehicles | Specific challenge: Range limitation, due to the limited storage capacity of electric batteries, is one of the major drawbacks of electric vehicles. The main challenge will be to achieve a systematic energy management of the vehicle based on the integration of components and sub-systems. The problem is worsened by the need to use part of the storage capacity in order to feed auxiliary equipment such as climate control. In extreme conditions up to 50% of the batteries’ capacity is absorbed by these systems. The systematic management of energy in electric vehicles is a means to gain extended range without sacrificing comfort. The challenge is therefore to extend the range of electric vehicles in all weather conditions […] |
As you can see, you have pre-processing widgets with different functions (Transformation, Tokenization, Normalization, Filtering, N-grams and POS tagger), word clouds, corpus viewers and almost everything you need to set up your workflow.
Results
Clustering
Remember, we are using no-code NLP. We have not written a single line. As a first result and after using the cosine distance widget, these are the 10 clusters obtained from Hierarchical Clustering.

Topic Modeling
Regarding Topic ModelingI used the LDA algorithm with 10 topics and this is where the magic happens: Orange3’s visualization capabilities allow us to select one of the detected topics, show the words associated to it and, if we select any of them, we can see the topics associated to it to check the degree of closeness they have.

Conclusion
You tell me:
| Metrics | Result | Comments |
|---|---|---|
| Workflow design time | Low | Once you have a certain degree of fluency, the workflow design is very simple |
| Results analysis time | High | Let us not forget that this is the objective: to have as much time as possible for analysis. |
| Reusability | High | It will be up to you to experiment with it, but if your area of interest is not very broad, you will gradually refine your workflows to be able to reuse them. The trick is to design atomic tasks independent of the use case (and the data). |
The next example will be based on KNIME. For example, analyzing tweets on a topic?