

Hace unos meses quería probar la plataforma Orange3 para analizar cómo funciona una herramienta «no-code» y explorar datos mediante Procesado de Lenguaje Natural (NLP). Algo rápido. No quería «perder» mucho tiempo experimentando. Las preguntas eran muy básicas: cómo ingesto los datos, cómo los proceso, que tipo de tareas necesito, aplico técnicas tradicionales o modelos lenguaje, … Vamos por partes.
A qué me refiero con NLP sin código o no-code
De forma resumida: extraer conocimiento de un corpus de documentos sin necesidad de generar código. Tan simple como eso. Con todo lo que implica:
- No tienes que instalar Python ni R ni ningún otro lenguaje de programación (aunque venga muy bien conocerlos)
- Nada de entornos de desarrollo (IDE)
- No tendrás que luchar con errores de dependencias, sintaxis o actualización de librerías
- Nos centraremos en la lógica del problema: NLP es una herramienta para algo. Vamos a analizar qué quiero saber de ese «algo».
- ¿Estás más cómodo con los flujos de trabajo? ¿Con la programación visual? Es decir, NLP sin código. Ahi está la clave.
Vamos a empezar con las herramientas. Nada complicado. Sólo un primer vistazo como para quitar el miedo.
Herramientas que utilizo para NLP sin código o no-code
En este campo, tengo dos herramientas de cabecera: KNIME Analytics Platform y Orange Data Mining. Ambas Open Source. Esta vez, el ejemplo lo haré con Orange pero si os digo la verdad, ahora mismo sólo utilizo KNIME. Incluso he escrito un artículo para su revista en Medium. Os dejo las principales que tengo en el radar para estos temas.
| Herramienta | Website | Descarga | Recursos | YouTube | |
|---|---|---|---|---|---|
| KNIME Analytics Platform | knime | Mac / PC / Linux | Academia / Blog | @knime | KNIMETV |
| Orange Data Mining | orangedatamining | Mac / PC / Linux | Doc / Blog | @orangedataminer | Orange |
| Dataiku DSS | dataiku | All platforms and Cloud | Learn | @dataiku | Dataiku |
¿Por qué me gustan estas herramientas?
Y en particular, KNIME Analytics Platform.
- Disponen de versión Open Source. Si lo quieres utilizar en un entorno profesional, KNIME y Dataiku disponen de productos empresariales en sus versiones Server.
- Al ser una programación visual, la curva de aprendizaje para un lego en programación es menor. Eso no quiere decir que no sea interesante saber programar. De hecho, si dominas Python o R, sus integraciones te permitirán explotar mucho más sus capacidades.
- Todos ellos tienen canales de formación con tutoriales muy sencillos que te permiten empezar probando de forma muy sencilla. Y los resultados no son un «hola mundo». Son, o pueden ser, reales. Sólo depende los datos que consigas.
- Tienen comunidades de desarrollo muy activas: nuevos nodos, blogs, libros, … si alguna vez te atascas en algún sitio, échale un vistazo a los foros. Es probable que esté resuelto o por lo menos, te van a dar claves para avanzar.
- Disponibilidad de librerías, add-ons, extras centrados en temáticas concretas, por ejemplo NLP sin código.
- Consigues resultados de forma muy rápida que evita que te abandones su estudio.
Ejemplos NLP sin código no-code con datos reales
Vamos a empezar con un ejemplo. En este caso, vamos a utilizar Orange:
- Objetivo: en el entorno del programa de investigación de la Comisión Europea, Horizon2020, identificar los topics que están relacionados entre si dentro de las áreas de «Connected Car».
- Datos: Listado con los topics de las llamadas de H2020 con codeID, título y objetivos.
- He filtrado los topics relacionados con «connected car», «autonomous vehicle», «transportation», … para ver cómo se relacionan entre ellos.
- Aquí tenéis el enlace al fichero CSV con los datos en la web EU Open Data Portal.
- Herramientas: Orange3 con el add-on Text Mining. Aquí tenéis una lista con los diferentes widgets disponibles.
- Fue mi primera prueba con Orange3 así que los comentarios con bienvenidos. Os dejo un link con el flujo de trabajo para que no tengáis que generarlo desde cero.
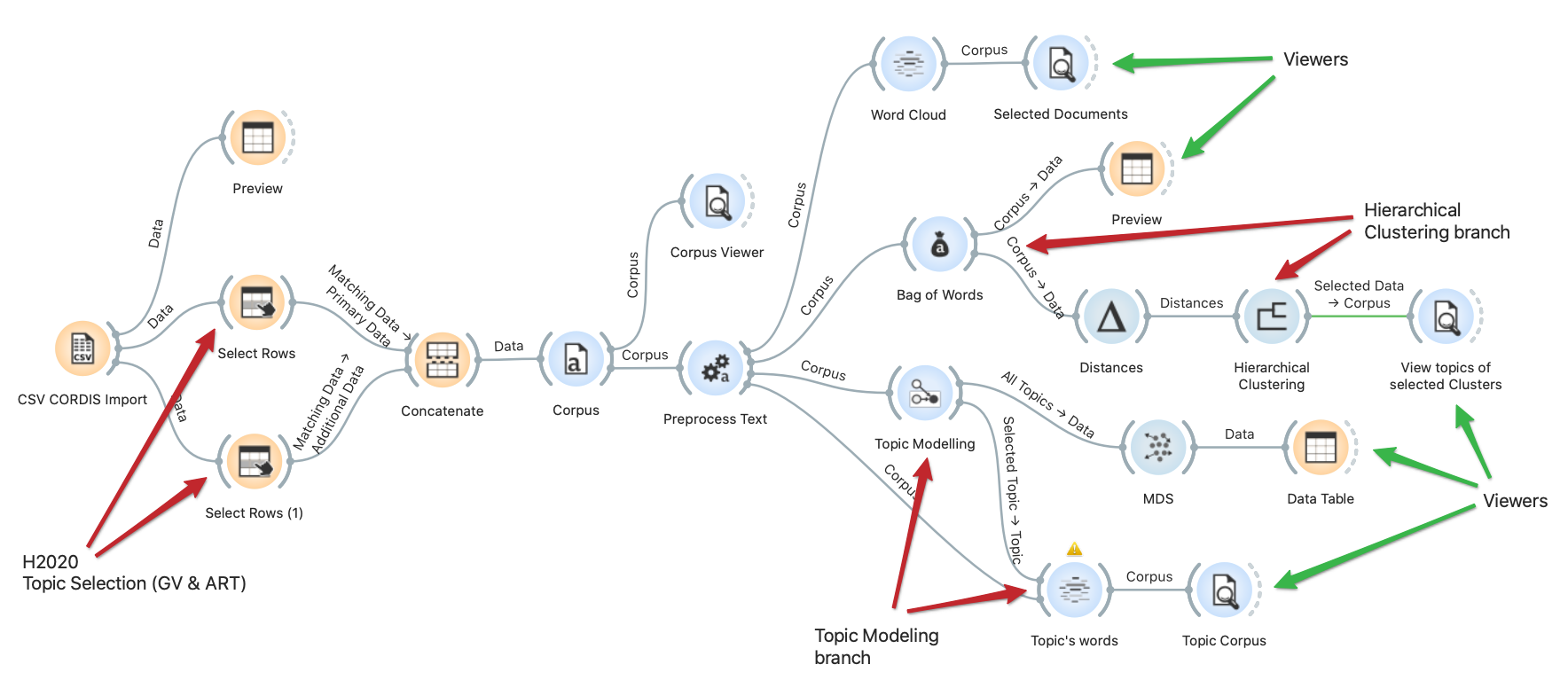
Ejemplo
Como os decía, he utilizado los topics en inglés relacionados con transporte *ART* y *GV*. En total son 43 topics que incluyen el codeID, el titulo y los objetivos del mismo. Por ejemplo:
| codeID | Título | Objetivo |
|---|---|---|
| GV-2-2014 | Optimised and systematic energy management in electric vehicles | Specific challenge: Range limitation, due to the limited storage capacity of electric batteries, is one of the major drawbacks of electric vehicles. The main challenge will be to achieve a systematic energy management of the vehicle based on the integration of components and sub-systems. The problem is worsened by the need to use part of the storage capacity in order to feed auxiliary equipment such as climate control. In extreme conditions up to 50% of the batteries’ capacity is absorbed by these systems. The systematic management of energy in electric vehicles is a means to gain extended range without sacrificing comfort. The challenge is therefore to extend the range of electric vehicles in all weather conditions […] |
Como podéis comprobar, disponéis de widgets de pre-procesado con diferentes funciones (Transformation, Tokenization, Normalization, Filtering, N-grams y POS tagger), nubes de palabras, visores de corpus y casi todos los necesarios para montar vuestro flujo de trabajo.
Resultados
Clustering
Recordad, estamos utilizando NLP sin código. No hemos escrito ni una línea. Como primer resultado y después de utilizar el widget de distancias por coseno, estos son los 10 clusters que obtenemos del Hierarchical Clustering.

Topic Modeling
En cuanto al Topic Modeling, he utilizado el algoritmo LDA con 10 topics y aqui es donde se produce la magia: las capacidades de visualización de Orange3 nos permite seleccionar uno de los topics detectados, mostrar las palabras asociadas al mismo y, si seleccionamos alguna de ella, podemos ver los topics asociados a la misma para comprobar el grado de cercanía que tienen.

Conclusión
Decídmelo vosotros:
| Métrica | Resultado | Comentarios |
|---|---|---|
| Tiempo de diseño del workflow | Bajo | Una vez que se tiene cierta soltura, el diseño de los workflow es muy sencillo |
| Tiempo de análisis de resultados | Alto | No olvidemos que este es el objetivo: disponer del mayor tiempo posible para el análisis. |
| Capacidad de reutilización | Alta | Sereis vosotros los que lo experimentéis pero si vuestro area de interés no es muy amplia, poco a poco iréis afinando los workflows para poder reutilizarlos. El truco está en diseñar tareas atómicas independientes del caso de uso (y de los datos). |
El próximo ejemplo estará basado en KNIME. Por ejemplo, ¿analizar los tweets de un tema?



