As many of you know, lately I am focusing on the no-code / low-code KNIME platform to explore flexible solutions to both data processing (ETL) and natural language processing (NLP) challenges.
One of these challenges is using the latest language models such as GPT3 or those available in the HuggingFace hub within KNIME as components. In this way, non-technical profiles will be able to take advantage of their capabilities in tasks such as topics classification, unstructured information extraction, or text generation without having to code.
This time, my colleagues Alejandro Ruberte and Miguel Salmeron have given me a hand with the Python programming part.
Just an intro to GPT3
In the last years we have seen how AI algorithms and models have been widely developed. One of the last shocking advancements around this topic is the release of GPT3, the biggest NLP (Natural Language Processing) model at the time of its release, done by OpenAI.
This model has been developed by keeping the focus on the text-generation task. Do you wonder why? Well, this task allows us to design any other NLP task we want having a small bunch of examples or even any example at all. These ways of using the model are the so-called few-shots (including one-shot) and zero-shot approaches, respectively.
Knowing that GPT3 could be considered as a highly generalist model, that will have fewer problems when adapting to ‘new’ tasks. This made us think about how we could design a more generic and user-friendly approach to use this model in KNIME, which leads to our workflow. Let’s start by defining the challenge we face in a sufficiently abstract way so that we can generalize it into a component within KNIME.
Use case: Topic description or naming
Imagine that you are asked about the latest topics that are being discussed in the bibliography on a particular topic, e.g. quantum computing. How would you give an answer? What would be your mental scheme? In what major tasks would you have to divide the problem in order to give an initial analysis? And above all, how do you organize it to be able to reprocess the documents in case they change?
Let’s start with the information sources: in this case, we can choose a source that aggregates all that information about articles, conferences, books, reviews, … Semantic Scholar.
The two main reasons for choosing S2 would be: first, it is a free tool with more than 203 million documents and, second, it has an API that allows us to consult it in an automated way. In addition, its API has a number of AI-enhanced functions that make it very interesting for automatic processing.
Once we have the data (the documents), we will start processing them. There are infinite techniques within the NLP area that we could do but we will focus on topic discovery or topic modeling. Here KNIME with its node “Topic Extractor (Parallel LDA)” will be able to help us. Here is some information on how an LDA (Latent Dirichlet Allocation) model works.
Remember that we have been asked to organize the bibliography by the topics the documents talk about. One of the problems with Topic Modeling is that to describe the clusters of documents it has generated, it uses the most relevant keywords of each cluster but does not describe the cluster. This is where GPT3 and its text generation capabilities come to our rescue.
Objective: few-shots and let GPT3 component do the magic
As the tables are the most common data type used in KNIME, almost all the capabilities are designed for their manipulation, their data visualization, etc. This made us clear that we had to focus on this type of data, and we decided to make a kind of ‘fill the table’ component. The initial definition by a profile closer to the business of our component could be:
“I need a component that takes some input data (the cluster keywords) and generates a descriptive text for that cluster. To help the model, I can generate some example output.”
One of our business analyst colleagues after discussing it with a manager
So, it would seem that we would have to design an “information completion” component.
The workflow
After some iterations, this is the proposed workflow with the different stages. In this case, we have used different resource types: Standard Components and Python packages. We will now describe it in detail:
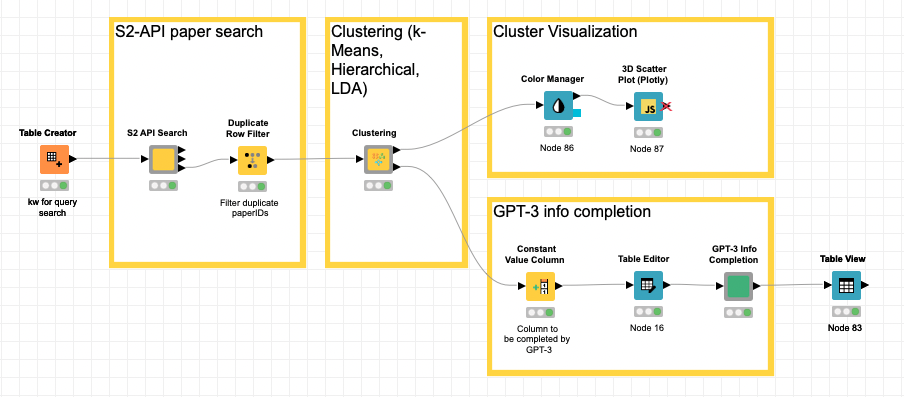
- Given a set of keywords for our searches, they are included in the table that will trigger the process.
- We will make a request to S2 to retrieve a given number of papers for each of the keywords and the embeddings of each of them with the rest of the associated information: title, abstract, TLDR, citations, …. It will be our component “S2 API Search“.
- Once we have the information from the documents (S2 papers), we will proceed to apply two distance-based (k-means and hierarchical) and one LDA-based clustering techniques. We have encapsulated it in a component so that it can be reused if necessary. It is the component named “Clustering“. The outputs are as follows
- Article/Paper metadata: paperID, title, abstract, citations, TLDR, year, and the original query
- Associated cluster by each technique. For LDA, we include the weights of each topic.
- Reduction using the t-SNE algorithm to 3 dimensions based on the embeddings (768 dims) of each document.
- Terms for detected LDA topics.
- With these results:
- We can represent the documents in 3D space using the standard plotly component.
- We use it as input to the GPT3 description branch of each of the topics. The main component will be the custom-defined “GPT3 Info Completion“.
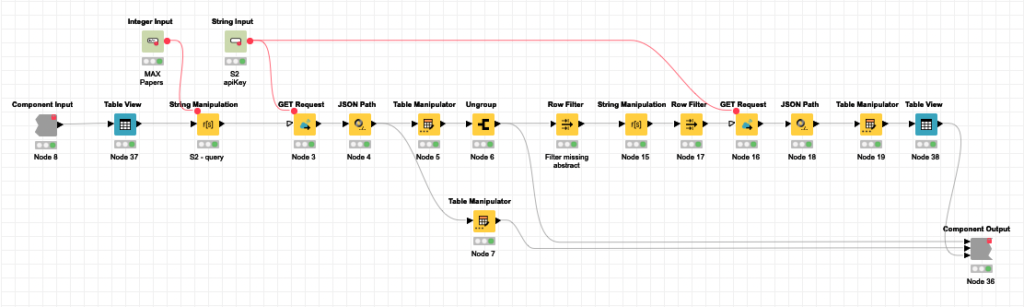
[S2 API Search] component
Here you can see the detail of the component. I won’t go too much into the specifics but everything revolves around the GET Request and JSON Path nodes to manage the API calls to Semantic Scholar. If you have an API-Key, you can use the service with a much higher transfer rate.
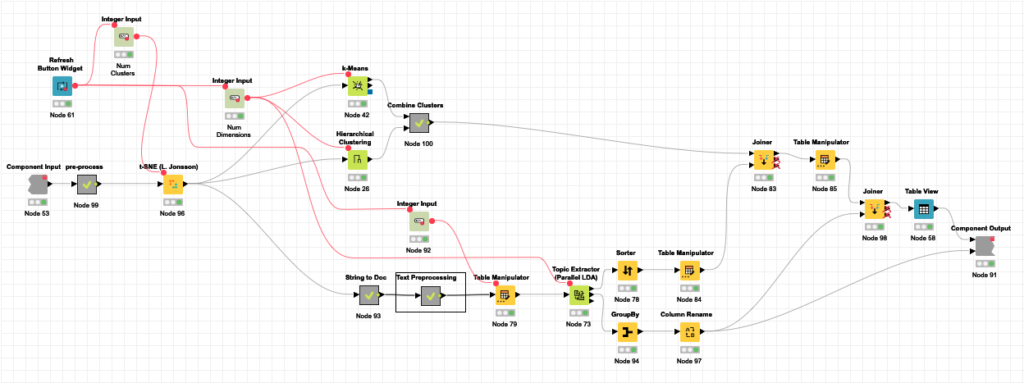
[Clustering] component
The same with the Clustering component. As I mentioned before, three processes are performed in parallel:
- K-Means & Hierarchical clustering based on SPECTER embeddings provided by S2. SPECTER is also available in Hugging Face repository.
- LDA Topic Extractor
The entire component is based on standard KNIME components. The level of complexity in the task that can be undertaken without generating a single line of code is very high as you can see.
[GPT3 Info Completion] component
In the first place, and talking about the KNIME components used, we can distinguish between three groups:
- Configuration nodes:
- As we wanted to allow the user to highly customize the task, we have set many of the relevant options in the component UI (User Interface). These nodes are used to create such an option and its default value at the UI. All of them are native to KNIME. If you want to read more about these components, click here.
- Conda Environment Propagation node:
- In order to avoid errors while trying to execute our component for the first time, we have used the recently added Conda Environment Propagation node, which checks if the correct virtual environment for the component is installed with all the requirements (taking care of their version) needed.
- Functional nodes:
- These nodes are the ones that differentiate a component from another, and where all processes take place. Our core functional nodes are the Python Script ones, but we also use other native nodes that are easier to use, like Row Filter, If Switch & End If, and more.
Python packages
First of all, we need all the packages required by the KNIME Python Script. Apart from that, we only need to install the transformers package (and its dependencies). There are low requirements in terms of packages for our component since we use OpenAI’s GPT3 model as an API. The transformers requirement is used only for added functions that aren’t critical for the execution. We will come over to this later.
Component details
In this last section, we will talk about the component from two different points of view. First, we will talk about the selected approach and what happens at the various stages inside the component (i.e., “What it does”). After that, we will talk about the UI, the meanings of the different available options, inputs, and outputs (i.e.,“How it is used”).
Component implementation
As we have said in earlier sections, our goal was to make an Information Completion component using GPT-3 (text-generation task). This fact leads inevitably to the design of a “prompt”, the structure of the input text, which will be filled with the available examples later. This structure is what is independent of the specific use case and must be generic. Due to the limitations that generality involves, we made a simple structure following these instructions:
Suppose a row (i) of the table we want to fill. This row will have already data-containing columns and others that we need to fill. Suppose there are rows in the table which have all the values for all required columns, so they can be used as examples.
With this information, the text input (prompt) will look like the following:
Inference of 'topic-description-gpt3' from 'topic-LDA-terms':
###
topic-LDA-terms: algorithm, key, code, security, cryptography
topic-description-gpt3: Quantum Security and Cryptography
###
topic-LDA-terms: quantum, algorithm, performance, design, implementation
topic-description-gpt3:Once defined how we will build the input for GPT3, we only needed to gather all the required information, like the user choice of columns to be used and the ones to be predicted, how many examples to use, the input table itself… i.e., the component configuration and inputs.
We can divide the Component into three main parts, as it is shown in the image below.
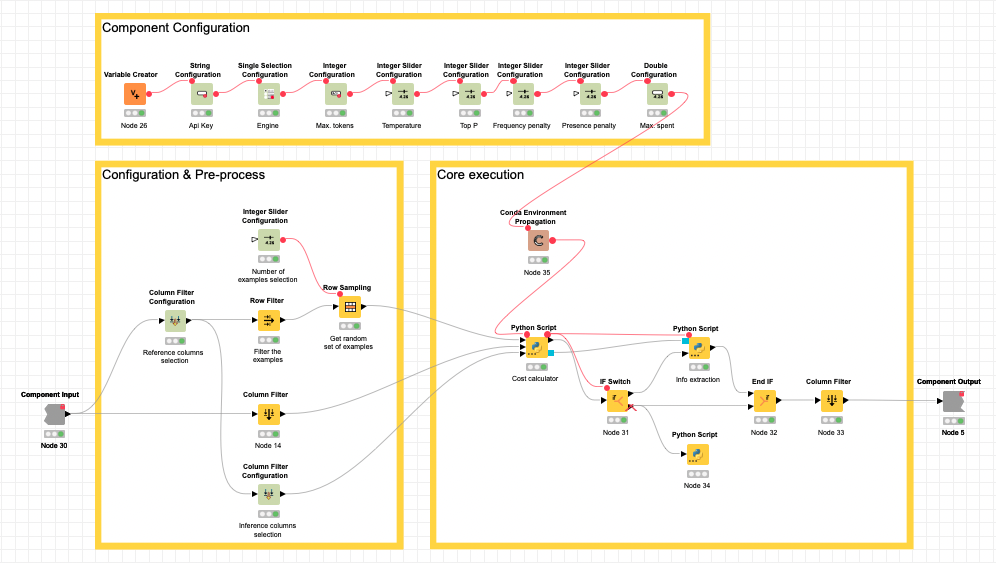
At Component configuration, we gather all the configuration options related to the parameters and consumption of GPT3.
At Configuration & pre-process, we gather the configuration related to what columns should be used, which ones should be predicted, and how many examples must be used. Also here is done a first stage of preprocessing, where we remove the non-string columns and select randomly all the possible examples (rows with all required data filled-in) until reaching the maximum if it is reached.
At Core executions, we receive all required configurations, the table that must be filled, and the examples gathered previously. Two main steps are done here. As it is expected to work with vast amounts of data, we have seen it necessary to be capable of managing the cost (as the GPT3 engine is not free) of the process. It is because of that that we ask the user for a maximum spent (in $).
As it was not possible for us to ‘ask’ GPT3 for the expected cost of each execution, we have included a Python Script node to build the prompts for every row that need to be filled, and use a GPT2 (also made by OpenAI) tokenizer to calculate the amount tokens that will be consumed, thus also the money it will cost (the cost per token during the execution of a specific engine is given here) by using this data among the selected configurations.
Just for clarification: a token is an approximation to meaningful pieces of text, like a word root (e.g. ‘liv’), termination (e.g. ‘ing’), negation (e.g. “n’t”), etc. What is considered as a ‘token’ highly depends on the tokenizer/model used.
After this calculation, if the expected cost of the execution is greater than the maximum set by the user, the execution stops showing a message informing of that, otherwise, the execution to the second step. Such a second step is where the prediction and fill-in are actually done, for every row, the program asks GPT3 engine to complete the input text with the required information, and we extract such information from the returned text and save it at the right location in the table. Finally, the filled-in table is returned.
Usage & UI Configuration
Our component is focused on fill-in in the input table so, first of all, our table must have cells without information. These cells must be labeled with “*” to ensure that it is expected to be overwritten by our Component, otherwise, it will leave the cell as it is.
Another consideration is that, for having examples to be used in building a few-shots task, there must be rows with all the columns that will be used (either as sources of information or as the ones that are wanted to be predicted). If there is not any, the task will be done as zero-shot, which could go well for the prediction of a single column, but if more is asked, it wouldn’t be strange to get low results. In order to avoid those cases, you should create at least one example (complete manually a row or create a ‘fake’ one with coherent data) using the Table Editor component in the workflow.
Now, talking about the UI and the configuration options, many of them are the same as expected by OpenAI, which are well explained here. Those parameters are:
- ‘Model’ (‘engine’ at OpenAI)
- ‘Max. Tokens’
- ‘Temperature’ (we use a [0, 100] range instead of [0.0, 1.0], but it is the same, i.e. 58 > 0.58)
- ‘Top P’ [0, 100]
- ‘Presence Penalty’ [-200, 200]
- ‘Frequency Penalty’ [-200, 200]
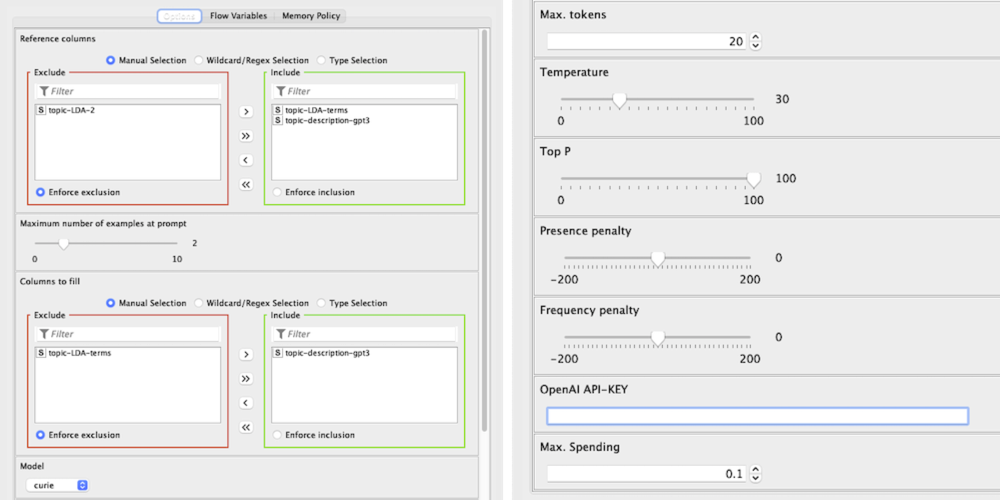
We explain the other ones below:
- Reference columns: Here we select the columns that will be used as source of information and the ones that will be filled in case of not having a value. A useful example (at prompt) will be built from a row with all these columns filled with data.
- The maximum number of examples at prompt: This parameter, an integer between 0 and 10, will set a limit to the examples used at the prompt. It is an important one as, depending on the task, a low value could lead to low performance, but a high value could lead to an unnecessary cost (e.g., if ‘1’ is selected, approximately 50% of the cost is because of the examples, depending on how optimized are the other parameters).
- Columns to fill: From the columns selected as Reference Columns, here you choose which ones are going to be filled if there is some “*”.
- OpenAI API-KEY: One of your apiKey from OpenAI, is needed to run properly the component as, without it, the GPT3 component cannot be used. Please, note that the cost of the executions will be paid by the owner of such apiKey.
- Max. Spending: The largest amount of money you are willing to pay for the configured execution. The expected cost will be calculated during the execution and, if it exceeds the value of this parameter, the execution will stop without calling GPT3 (so there would be no spent at all). With all this information, you should be able to use the component without problems and understand how to optimize such executions. Please note that the returned table will have the same STRING columns as the original one, but the other ones will not be preserved.
Results
Let’s say that, as I indicated at the beginning, we have been asked (q) to make a preliminary analysis of the main topics around quantum computing: quantum use cases, quantum computing chips, quantum photonics, quantum crypto cybersecurity. These would be the results of each of the stages.
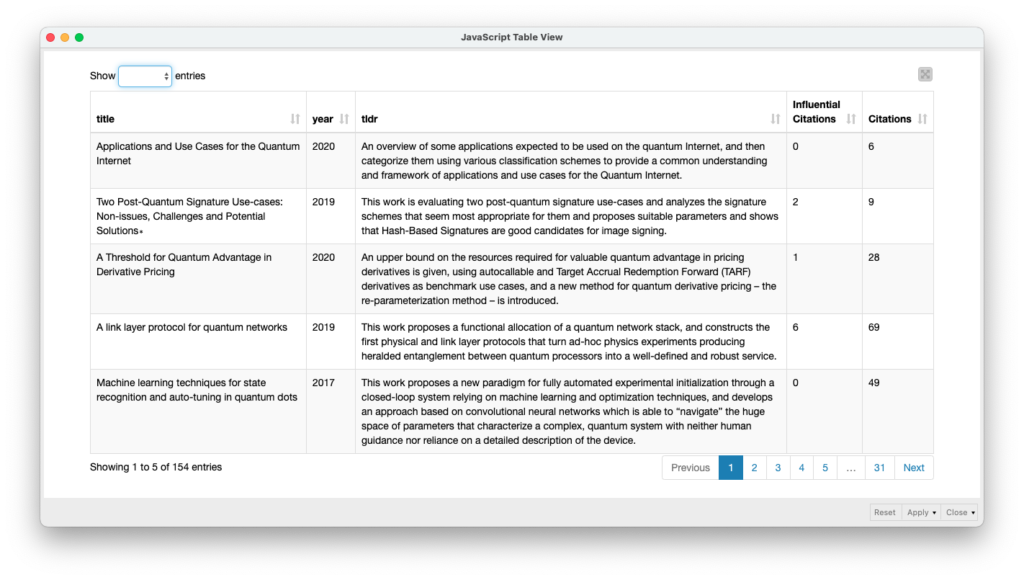
S2 API Search Component
Here is a table with random examples of the articles available in Semantic Scholar from the queries requested as input (q).
Clustering Component
In addition to the classification using the different techniques we have discussed (k-Means, Hierarchical, and LDA), here is a 3D graphical representation of the cluster identifier using k-Means based on their embeddings.

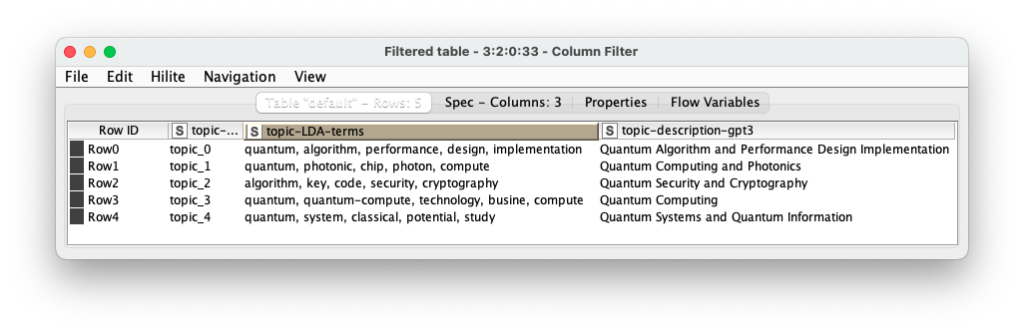
GPT3 Info Completion
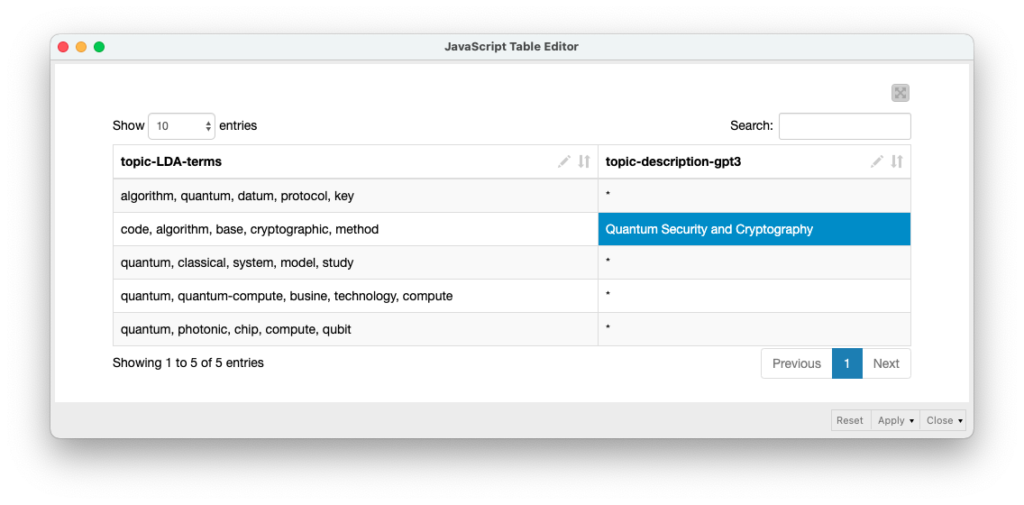
Here are the results of the inference or information completion of the description of the topics based on the keywords provided by the LDA stage. In this case, only row 2 has been provided as an example for the Davinci engine of GPT3.
Download workflow
You can download the workflow from KNIME Hub in this link.
Final Considerations
It is very exploratory work and has room for improvement but what would be the main insights?
- With very little effort, we have been able to automate a task that can be very time-consuming if we want to do it manually.
- Except for the development of the KNIME GPT-3 Component, the rest has been generated using the standard components provided by KNIME as a no-code tool.
- We can mix no-code with low-code (Python-based in this case) to increase the capabilities of the platform.
- By working towards the generation of components, the rate of reuse by other team members or to add new functionality is very high.
- The use of workflow by non-technical profiles has virtually no barrier to entry.
Improvements
This is a very exploratory exercise but it already allows us to see the potential of the approach used. Some improvements that I’m already implementing:
- Automatic determination of the optimal cluster number, e.g. with the elbow method.
- Choice of the different types of graphic representation according to the chosen dimensions, 2D or 3D.
- Automatic generation of the GPT3 prompt using the latest InstructGPT models released by OpenAI.
- Exploit the multilingual capabilities of GPT3.
If you have any suggestions, I will be more than open to discussing them… and trying them out. Leave me a comment and we’ll get in touch.
Just one more thing…
By the way, the task has changed: the topic was not Quantum Computing but Edge Computing. Sorry for the short notice. Could you have the analysis this afternoon? 😉
Heard in any Research office
And if you’ve made it this far, you might want to take a look at this report that my colleagues from NTT DATA and Barcelona Digital Talent have generated on the impact of low-code tools as an accelerator of digital transformation.