Como muchos de vosotros sabéis, últimamente me estoy centrando en la plataforma KNIME no-code / low-code para explorar soluciones flexibles tanto para el procesamiento de datos (ETL) como para el procesamiento del lenguaje natural (NLP).
Uno de estos retos es utilizar como componentes los últimos modelos de lenguaje, como GPT3 o los disponibles en el hub HuggingFace dentro de KNIME. De este modo, los perfiles no técnicos podrán aprovechar sus capacidades en tareas como la clasificación de temas, la extracción de información no estructurada o la generación de textos sin tener que programar.
Esta vez, mis compañeros Alejandro Ruberte y Miguel Salmerón me han echado una mano con la parte de programación en Python.
Una pequeña introducción a GPT3
En los últimos años hemos visto cómo se han desarrollado ampliamente los algoritmos y modelos de IA. Uno de los últimos avances más relevantes en torno a este tema es el lanzamiento de GPT3, el mayor modelo de NLP (Procesamiento del Lenguaje Natural) en el momento de su lanzamiento, realizado por OpenAI.
Este modelo se ha desarrollado especificamente para la tarea de generación de textos. ¿Te preguntas por qué? Pues bien, esta tarea nos permite diseñar cualquier otra tarea de NLP que queramos disponiendo de un pequeño grupo de ejemplos o incluso sin ninguno de ellos. Estas formas de utilizar el modelo son los llamados estrategias de few-shots(incluyendo un solo ejemplo o one-shot) y de zero-shot, respectivamente.
Sabiendo que GPT3 podría considerarse como un modelo altamente generalista, que tendrá menos problemas a la hora de adaptarse a «nuevas» tareas. Esto nos hizo pensar en cómo podríamos diseñar un enfoque más genérico y fácil de usar para utilizar este modelo en KNIME, lo que nos lleva a nuestro flujo de trabajo. Empecemos por definir el reto al que nos enfrentamos de una forma lo suficientemente abstracta como para poder generalizarlo en un componente dentro de KNIME.
Caso de uso: Descripción o denominación de topics
Imagina que te preguntan por los últimos temas que se están tratando en la bibliografía sobre un tema concreto, por ejemplo, la computación cuántica. ¿Cómo darías una respuesta? ¿Cuál sería tu esquema mental? ¿En qué tareas principales tendría que dividir el problema para dar un primer análisis? Y sobre todo, ¿cómo se organiza para poder volver a procesar los documentos en caso de que cambien?
Empecemos por las fuentes de información: en este caso, podemos elegir una fuente que agregue toda esa información sobre artículos, conferencias, libros, reseñas, … Semantic Scholar.
Las dos razones principales para elegir S2 serían: primero, que es una herramienta gratuita con más de 203 millones de documentos y, segundo, que tiene una API que nos permite consultarla de forma automatizada. Además, su API tiene una serie de funciones mejoradas por la IA que la hacen muy interesante para el procesamiento automático.
Una vez que tengamos los datos (los documentos), empezaremos a procesarlos. Hay infinidad de técnicas dentro del área de la NLP que podríamos hacer, pero nos centraremos en el descubrimiento de topics o topic modeling. Aquí KNIME con su nodo«Extractor de Temas (LDA Paralelo)» podrá ayudarnos. A continuación se explica cómo funciona un modelo LDA (Latent Dirichlet Allocation).
Recuerda que nos han pedido que organicemos la bibliografía por los temas de los que hablan los documentos. Uno de los problemas del Topic Modeling es que para describir los clusters de documentos que ha generado, utiliza las palabras clave más relevantes de cada cluster pero no describe el cluster en si mismo. Aquí es donde GPT3 y sus capacidades de generación de texto vienen a nuestro rescate.
Objetivo: algunos ejemplos y dejar que el componente GPT3 haga la magia
Como las tablas son el tipo de datos más comúnmente utilizado en KNIME, casi todas las capacidades están diseñadas para su manipulación, su visualización de datos, etc. Esto nos hizo ver que teníamos que centrarnos en este tipo de datos, y decidimos hacer una especie de componente de «completar la tabla«. La definición inicial por un perfil más cercano al negocio de nuestro componente podría ser:
«Necesito un componente que tome unos datos de entrada (las palabras clave del cluster) y genere un texto descriptivo para ese cluster. Para ayudar al modelo, puedo generar alguna salida de ejemplo».
Uno de nuestros colegas analistas de negocios después de discutirlo con un gerente
Por lo tanto, parece que tendríamos que diseñar un componente de «information completion».
El flujo de trabajo
Después de algunas iteraciones, este es el flujo de trabajo propuesto con las diferentes etapas. En este caso, hemos utilizado diferentes tipos de recursos: Componentes estándar y paquetes de Python. A continuación lo describiremos en detalle:
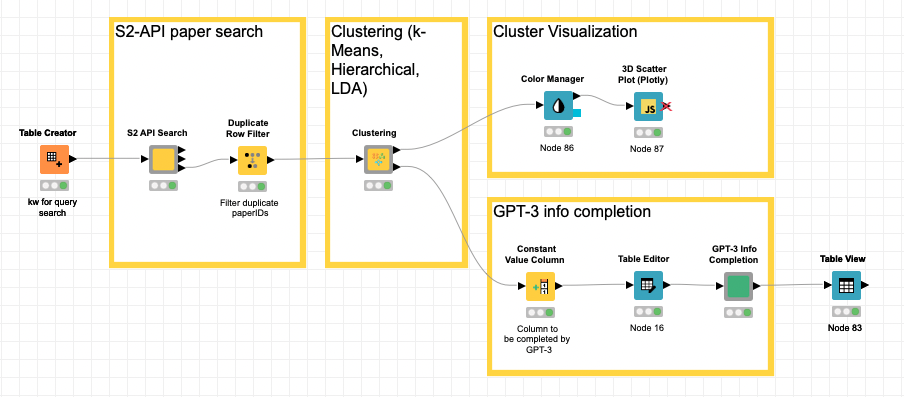
- Dado un conjunto de palabras clave para nuestras búsquedas, se incluyen en la tabla que desencadenará el proceso.
- Haremos una petición a S2 para que recupere un número determinado de artículos para cada una de las palabras clave y los embeddings de cada uno de ellos con el resto de la información asociada: título, resumen, TLDR, citas, …. Será nuestro componente «S2 API Search«.
- Una vez que tengamos la información de los documentos (S2 papers), procederemos a aplicar dos técnicas de clustering basadas en la distancia (k-means y jerárquica) y una basada en LDA. Lo hemos encapsulado en un componente para poder reutilizarlo si es necesario. Es el componente denominado «Clustering«. Los resultados son los siguientes
- Metadatos del artículo/paper: paperID, título, resumen, citas, TLDR, año y la consulta original
- Cluster asociado por cada técnica. Para el LDA, incluimos las ponderaciones de cada topic.
- Reducción mediante el algoritmo t-SNE a tres dimensiones a partir de los embeddings (768 dims) de cada documento.
- Términos de los topics LDA detectados.
- Con estos resultados:
- Podemos representar los documentos en el espacio 3D utilizando el componente estándar plotly.
- Lo utilizamos como entrada a la rama de descripción GPT3 de cada uno de los temas. El componente principal será el «GPT3 Info Completion» definido a medida.
Componente [Búsqueda API S2
Aquí puede ver el detalle del componente. No entraré demasiado en los detalles, pero todo gira en torno a los nodos GET Request y JSON Path para gestionar las llamadas a la API de Semantic Scholar. Si tienes una API-Key, puedes utilizar el servicio con una tasa de transferencia mucho mayor.
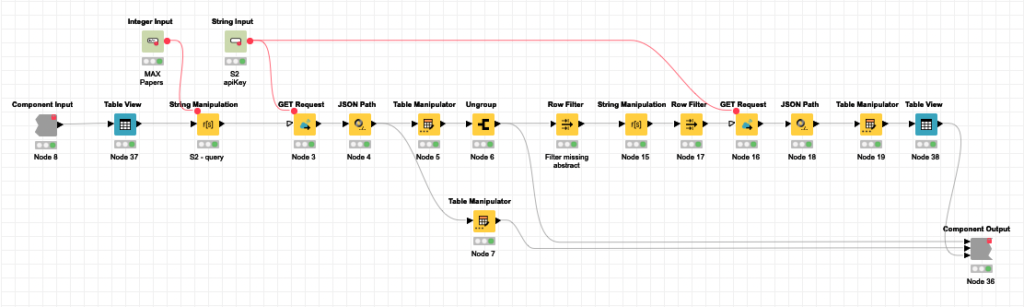
Componente [Clustering]
Lo mismo ocurre con el componente Clustering. Como he mencionado antes, se realizan tres procesos en paralelo:
- K-Means y clustering jerárquico basado en SPECTER embeddings proporcionados por S2. SPECTER también está disponible en el repositorio Hugging Face.
- LDA Topic Extractor
Todo el componente se basa en los componentes estándar de KNIME. El nivel de complejidad de la tarea que se puede acometer sin generar una sola línea de código es muy alto, como se puede ver.
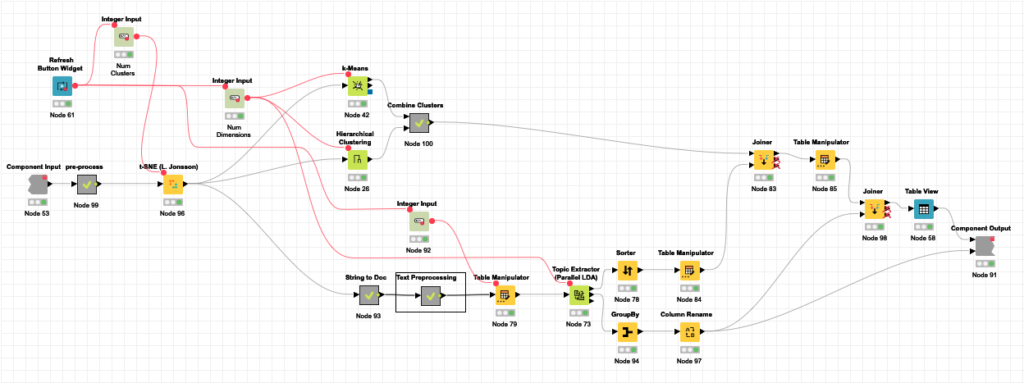
Componente [GPT3 Info Completion].
En primer lugar, y hablando de los componentes KNIME utilizados, podemos distinguir tres grupos:
- Nodos de configuración:
- Como queríamos permitir al usuario una gran personalización de la tarea, hemos configurado muchas de las opciones relevantes en el componente UI (User Interface). Estos nodos se utilizan para crear dicha opción y su valor por defecto en la UI. Todos ellos son nativos de KNIME. Si quiere leer más sobre estos componentes, haz clic aquí.
- Nodo de propagación del entorno Conda:
- Para evitar errores al intentar ejecutar nuestro componente por primera vez, hemos utilizado el recientemente añadido nodo de Propagación de Entornos de Conda, que comprueba si el entorno virtual correcto para el componente está instalado con todos los requisitos (atendiendo a su versión) necesarios.
- Nodos funcionales:
- Estos nodos son los que diferencian un componente de otro, y donde tienen lugar todos los procesos. Nuestros nodos funcionales principales son los de Python Script, pero también utilizamos otros nodos nativos que son más fáciles de usar, como Row Filter, If Switch & End If, y más.
Paquetes de Python
En primer lugar, necesitamos todos los paquetes requeridos por el KNIME Python Script. Aparte de eso, sólo tenemos que instalar el paquete de transformers (y sus dependencias). Hay pocos requisitos en términos de paquetes para nuestro componente ya que utilizamos el modelo GPT3 de OpenAI como API. El requisito de los transformers se utiliza sólo para las funciones añadidas que no son críticas para la ejecución. Ya hablaremos de esto más adelante.
Detalles del componente
En esta última sección, hablaremos del componente desde dos puntos de vista diferentes. En primer lugar, hablaremos del enfoque seleccionado y de lo que ocurre en las distintas etapas dentro del componente (es decir, «lo que hace»). A continuación, hablaremos de la interfaz de usuario, del significado de las diferentes opciones disponibles, de las entradas y de las salidas (es decir, «cómo se utiliza»).
Implementación del componente
Como hemos dicho en secciones anteriores, nuestro objetivo era hacer un componente de completamiento de información usando GPT-3 (tarea de generación de texto). Este hecho conduce inevitablemente al diseño de un «prompt«, la estructura del texto de entrada, que se completará con los ejemplos disponibles más adelante. Esta estructura es la que es independiente del caso de uso específico y debe ser genérica. Debido a las limitaciones que implica la generalidad, hemos realizado una estructura sencilla siguiendo estas instrucciones:
Supongamos una fila (i) de la tabla que queremos rellenar. Esta fila tendrá columnas que ya contienen datos y otras que debemos rellenar. Supongamos que hay filas en la tabla que tienen todos los valores para todas las columnas requeridas, por lo que se pueden utilizar como ejemplos.
Con esta información, la entrada de texto (prompt) tendrá el siguiente aspecto:
Inference of 'topic-description-gpt3' from 'topic-LDA-terms':
###
topic-LDA-terms: algorithm, key, code, security, cryptography
topic-description-gpt3: Quantum Security and Cryptography
###
topic-LDA-terms: quantum, algorithm, performance, design, implementation
topic-description-gpt3:Una vez definido cómo vamos a construir la entrada para GPT3, sólo nos faltaba recopilar toda la información necesaria, como la elección por parte del usuario de las columnas que se van a utilizar y las que se van a predecir, cuántos ejemplos se van a utilizar, la propia tabla de entrada… es decir, la configuración de los componentes y las entradas.
Podemos dividir el componente en tres partes principales, como se muestra en la imagen siguiente.
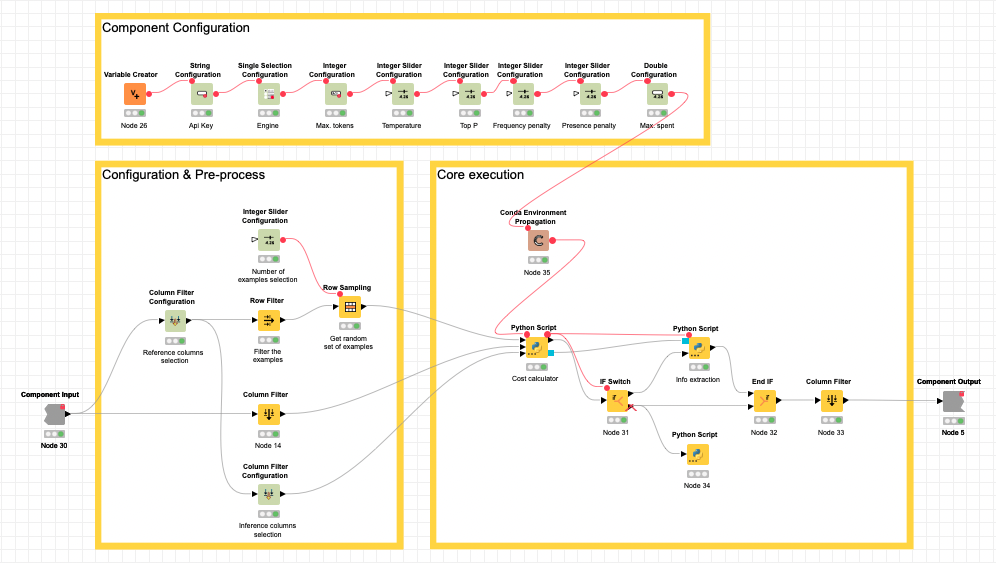
En Configuración del componente, recogemos todas las opciones de configuración relacionadas con los parámetros y el consumo de GPT3.
En Configuración y preprocesamiento, recogemos la configuración relacionada con qué columnas deben utilizarse, cuáles deben predecirse y cuántos ejemplos deben utilizarse. También aquí se hace una primera etapa de preprocesamiento, en la que se eliminan las columnas que no son cadenas y se seleccionan aleatoriamente todos los ejemplos posibles (filas con todos los datos requeridos rellenados) hasta llegar al máximo si se alcanza.
En la Core execution, recibimos todas las configuraciones requeridas, la tabla que hay que rellenar y los ejemplos recogidos previamente. Aquí se realizan dos pasos principales. Como se espera que trabaje con grandes cantidades de datos, hemos visto necesario que sea capaz de gestionar el coste (como el GPT3 motor no es gratuito) del proceso. Es por ello que pedimos al usuario un gasto máximo (en $).
Como no nos ha sido posible «preguntar» a GPT3 por el coste previsto de cada ejecución, hemos incluido un nodo Python Script para construir los avisos de cada fila que haya que rellenar, y utilizamos un tokenizador GPT2 (también hecho por OpenAI) para calcular la cantidad de tokens que se consumirán, y por tanto también el dinero que costará ( aquí se da el coste por token durante la ejecución de un motor concreto) utilizando estos datos entre las configuraciones seleccionadas.
Sólo para aclarar: un token es una aproximación a fragmentos de texto con significado, como una raíz de palabra (por ejemplo, «liv»), una terminación (por ejemplo, «ing»), una negación (por ejemplo, «n’t»), etc. Lo que se considera un «token» depende en gran medida del tokenizador/modelo utilizado.
Tras este cálculo, si el coste esperado de la ejecución es mayor que el máximo fijado por el usuario, la ejecución se detiene mostrando un mensaje informando de ello, en caso contrario, la ejecución pasa al segundo paso. En este segundo paso es donde se realiza realmente la predicción y el relleno, para cada fila, el programa pide al motor GPT3 que complete el texto de entrada con la información requerida, y nosotros extraemos dicha información del texto devuelto y la guardamos en el lugar adecuado de la tabla. Finalmente, se devuelve la tabla rellenada.
Uso y configuración de la interfaz de usuario
Nuestro componente está enfocado a rellenar la tabla de entrada por lo que, en primer lugar, nuestra tabla debe tener celdas sin información. Estas celdas deben ser etiquetadas con «*» para asegurar que se espera que sea sobrescrita por nuestro Componente, de lo contrario, dejará la celda como está.
Otra consideración es que, para tener ejemplos que se usen en la construcción de una tarea de few-shots, debe haber filas con todas las columnas que se usarán (ya sea como fuentes de información o como las que se quieren predecir). Si no hay ninguno, la tarea se hará como zero-shot, lo que podría ir bien para la predicción de una sola columna, pero si se pide más, no sería extraño obtener resultados bajos. Para evitar estos casos, debería crear al menos un ejemplo (completar manualmente una fila o crear una «falsa» con datos coherentes) utilizando el componente Editor de tablas en el flujo de trabajo.
Ahora, hablando de la UI y de las opciones de configuración, muchas de ellas son las mismas que espera OpenAI, las cuales están bien explicadas aquí. Esos parámetros son:
- Modelo («motor» en OpenAI)
- ‘Max. Tokens’
- ‘Temperatura‘ (utilizamos un rango [0, 100] en lugar de [0,0, 1,0], pero es lo mismo, es decir, 58 > 0,58)
- ‘Top P’ [0, 100]
- ‘Presence Penalty’ [-200, 200]
- ‘Frequency Penalty’ [-200, 200]
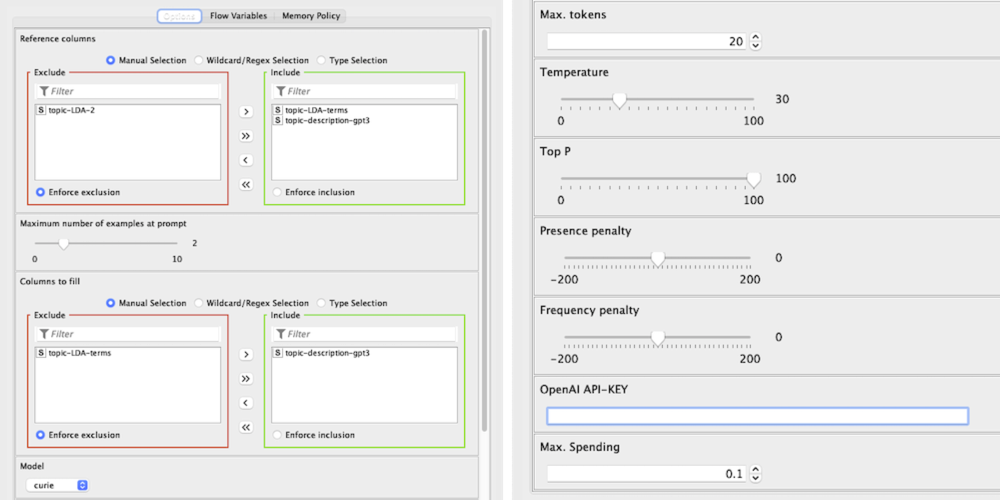
A continuación explicamos los demás:
- Columnas de referencia: Aquí seleccionamos las columnas que se utilizarán como fuente de información y las que se rellenarán en caso de no tener un valor. Un ejemplo útil (en el prompt) se construirá a partir de una fila con todas estas columnas llenas de datos.
- El número máximo de ejemplos en el prompt: Este parámetro, un número entero entre 0 y 10, establecerá un límite a los ejemplos utilizados en el prompt. Es importante, ya que, dependiendo de la tarea, un valor bajo podría provocar un bajo rendimiento, pero un valor alto podría provocar un coste innecesario(por ejemplo, si se selecciona «1», aproximadamente el 50% del coste se debe a los ejemplos, dependiendo de lo optimizados que estén los demás parámetros).
- Columnas a rellenar: De las columnas seleccionadas como Columnas de referencia, aquí se elige cuáles se van a rellenar si hay algún «*».
- OpenAI API-KEY: Una apiKey de OpenAI es necesaria para ejecutar correctamente el componente ya que, sin ella, el componente GPT3 no puede ser utilizado. Por favor, tenga en cuenta que el coste de las ejecuciones será pagado por el propietario de dicha apiKey.
- Max. Spending: La mayor cantidad de dinero que está dispuesto a pagar por la ejecución configurada. El coste esperado se calculará durante la ejecución y, si supera el valor de este parámetro, la ejecución se detendrá sin llamar a GPT3 (por lo que no se gastaría nada). Con toda esta información, deberías ser capaz de utilizar el componente sin problemas y entender cómo optimizar dichas ejecuciones. Tenga en cuenta que la tabla devuelta tendrá las mismas columnas STRING que la original, pero las demás no se conservarán.
Resultados
Digamos que, como he indicado al principio, se nos ha pedido (q) que hagamos un análisis preliminar de los principales temas en torno a la computación cuántica: casos de uso cuántico, chips de computación cuántica, fotónica cuántica, ciberseguridad criptográfica cuántica. Estos serían los resultados de cada una de las etapas.
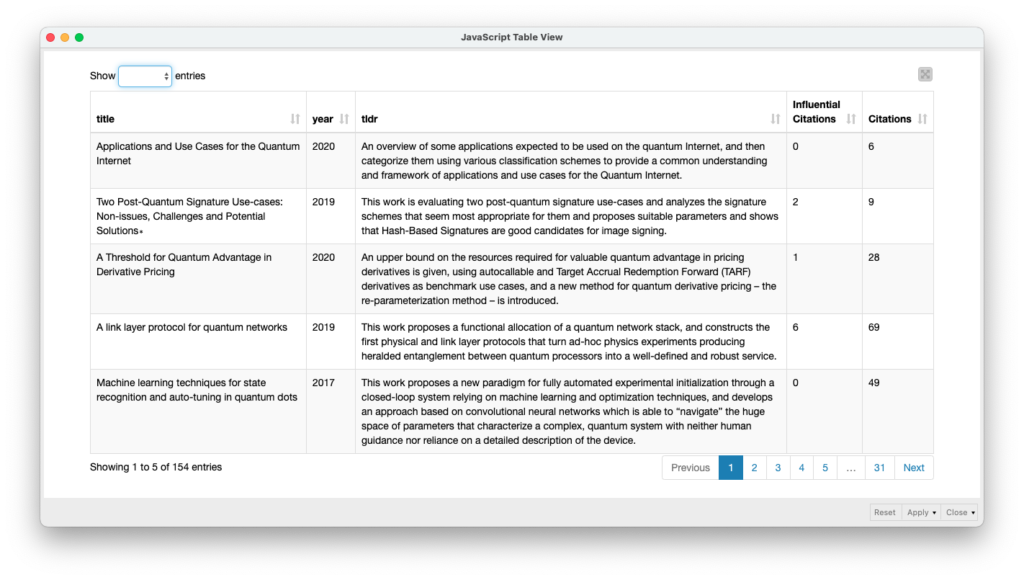
S2 API Search Component
A continuación se muestra una tabla con ejemplos aleatorios de los artículos disponibles en Semantic Scholar a partir de las consultas solicitadas como entrada (q).
Clustering Component
Además de la clasificación mediante las diferentes técnicas que hemos discutido (k-Means, Jerárquica y LDA), aquí se muestra una representación gráfica en 3D del identificador de clústeres mediante k-Means basado en sus embeddings.

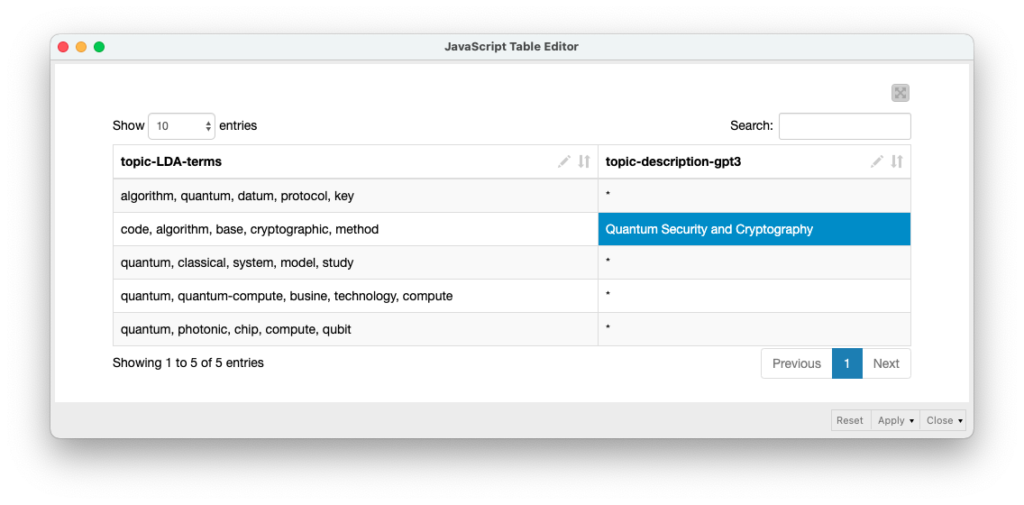
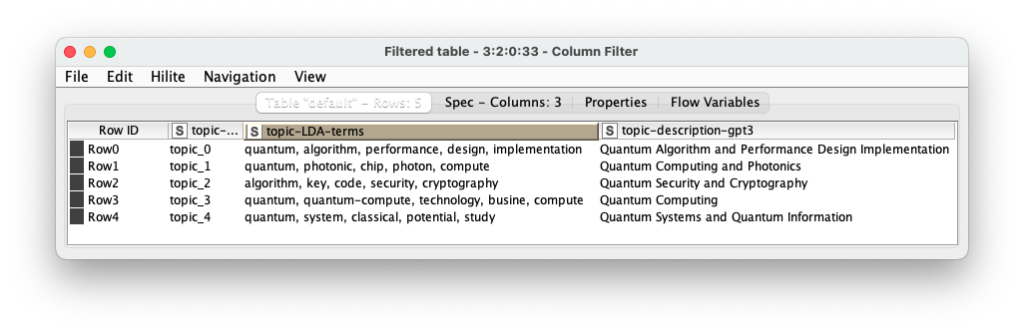
GPT3 Info Completion
A continuación se muestran los resultados de la inferencia o la finalización de la información de la descripción de los temas a partir de las palabras clave proporcionadas por la etapa LDA. En este caso, sólo se ha proporcionado la fila 2 como ejemplo para el motor Davinci de GPT3.
Descargar el flujo de trabajo
Puede descargar el flujo de trabajo desde KNIME Hub en este enlace.
Consideraciones finales
Es un trabajo muy exploratorio y tiene margen de mejora, pero ¿cuáles serían las principales conclusiones?
- Con muy poco esfuerzo, hemos podido automatizar una tarea que puede consumir mucho tiempo si la hacemos manualmente.
- Salvo el desarrollo del Componente KNIME GPT-3, el resto se ha generado utilizando los componentes estándar proporcionados por KNIME como herramienta no-code.
- Podemos mezclar no-code con low-code (basado en Python en este caso) para aumentar las capacidades de la plataforma.
- Al trabajar en la generación de componentes, la tasa de reutilización por parte de otros miembros del equipo o para añadir nuevas funcionalidades es muy alta.
- El uso del flujo de trabajo por parte de perfiles no técnicos no tiene prácticamente ninguna barrera de entrada.
Mejoras
Se trata de un ejercicio muy exploratorio, pero ya permite ver el potencial del enfoque utilizado. Algunas mejoras que ya estoy implementando:
- Determinación automática del número óptimo de conglomerados, por ejemplo, con el método del codo.
- Elección de los diferentes tipos de representación gráfica según las dimensiones elegidas, 2D o 3D.
- Generación automática del aviso GPT3 utilizando los últimos modelos InstructGPT publicados por OpenAI.
- Aprovechar las capacidades multilingües de GPT3.
Si tienes alguna sugerencia, estaré más que abierto a discutirla… y a probarla. Déjeme un comentario y nos pondremos en contacto.
Sólo una cosa más…
Por cierto, la tarea ha cambiado: el tema no era Quantum Computing sino Edge Computing. Disculpe la poca antelación. ¿Podría tener el análisis esta tarde? 😉
Oído en cualquier oficina de investigación
Y si has llegado hasta aquí, quizá quieras echar un vistazo a este informe que han generado mis compañeros de NTT DATA y Barcelona Digital Talent sobre el impacto de las herramientas de bajo código como acelerador de la transformación digital.